

Capabilities
What PRIZM DeliversThis multi-agent architecture platform runs with multiple autonomous, role-based agents across various capabilities such as Discovery, Quality, Catalog, Governance, Observability, and Remediation and share context continuously, so each new pipeline or AI workload added to the environment extends coverage without manual configuration. The three main capabilities Prizm delivers are
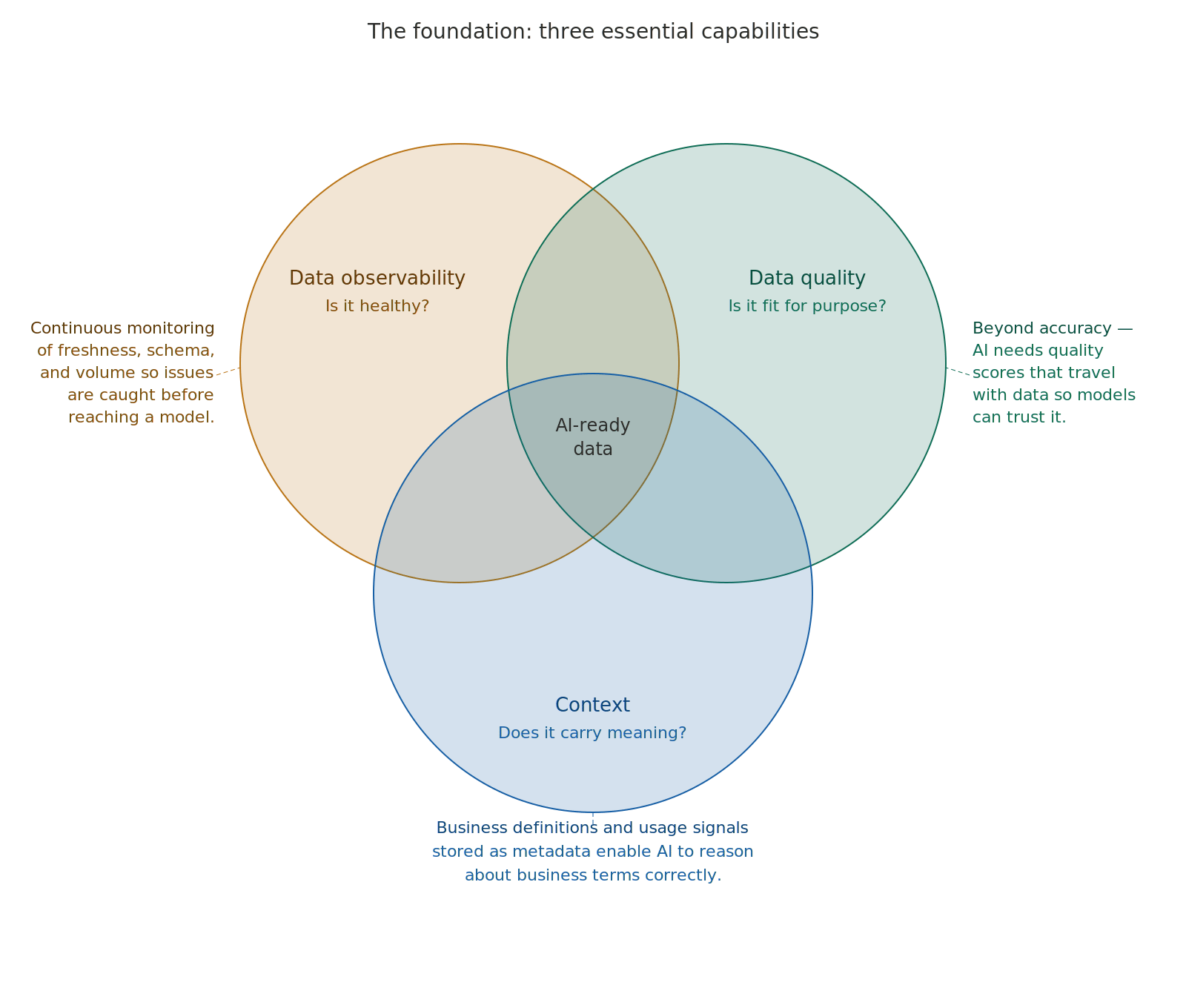
Observability
Is it healthy?Autonomous monitoring across pipelines, ware/lake houses, and BI tools, detecting data anomalies before they reach AI models.
Quality
Is it fit for purpose?Policy-driven rules, AI-suggested checks, and reusable quality scores travel with the data from raw ingest through to consumption.
Context
Does it have meaning?Make data findable, usable, and governed — surfacing lineage, ownership, and business meaning for both human users and AI agents.
Key features
Asset
Discover and catalog all tables, views, queries, pipelines, reports, and semantic models connected to your data sources. Search, filter, and drill into any asset to see its schema, lineage, and quality status.
Metric
Monitor key performance indicators including data quality scores, active pipeline counts, system uptime, and data volume. Track 30-day quality trends and pipeline execution status in real time.
Alert
Receive notifications when a metric threshold is breached, data drift is detected, a schema change occurs, or a pipeline fails. Alerts are classified by severity: Critical, High, Warning, and Info.
Issue
Track data quality problems from discovery through resolution. Issues are organized by status—New, In Progress, and Resolved—and linked to the affected asset and database.
Analytics
Explore query performance, cache hit rates, error rates, and active user counts. Use the Performance Overview to understand system behavior over time.
Converse
Ask questions about your data in natural language. The built-in chat assistant helps you find assets, understand metrics, and investigate issues without leaving the platform.
How PRIZM works
Connect your data sources
Link PRIZM to your data, pipelines and reporting platforms — Snowflake, PostgreSQL, MySQL, Redshift, DBT and others. PRIZM discovers assets across all connected sources and populates your asset catalog automatically.
Monitor automatically
Once connected, PRIZM continuously evaluates observability, quality and context across your assets. It tracks metrics such as operational (freshness, volume, schema stability), performance (execution time, usage, credits) , structural (completeness, distribution, frequency, statistics), business , reconciliation and surfaces anomalies as they occur.
Builds Context using governed metadata
Prizm’s criticality engine builds a continuously updated, living map of enterprise data by combining technical metadata, lineage, usage patterns, and business meaning into a single context layer. Unlike static catalogs, it continuously validates that context against live observability and quality signals, catching “context drift” before AI agents act on stale information and produce confidently wrong outputs.
PRIZM supports all leading data, pipeline, reporting and analytics platform connectivity. For a list of connectors supported, please check the Data Sources page